This article will help you develop an intuition-based understanding of Goal-Oriented Dialogue Generation in dialogue systems, with Few-Shot training and Knowledge Transfer Networks.
To be specific, we’ll learn about an unsupervised discrete sentence representation learning method that can integrate with any existing encoder-decoder dialogue model, for interpretable response generation using a minimal amount of data that is not annotated.
Why few-shot learning?
Deep Neural Networks have proved to be successful in data-intensive applications. Usually, as shown via conventional practice, a network having numerous parameters has a greater capacity to map the data, and more training data provides the network to have a better generalization.
Such neural networks, in lack of sufficient data, tend to struggle in fixing the weights and biases for the neurons. In contrast, the human brain having much more complex network architecture does not face any difficulty in adapting to new domains. Instead, it excels in learning new concepts with limited data.
Few-shot learning has, therefore, been proposed to close the performance gap between a machine learner and a human learner. In the canonical setting of few-shot learning, there is a known training set and unseen testing set with disjoint categories.
This unique setting of few-shot learning poses an unprecedented challenge in efficiently utilizing the prior information in the training set, which corresponds to the known information or historical information of the human learner.
Hence, NLP researchers leverage the knowledge learned by the main model to improve the performance measure of the architecture on target data.
A Look Inside Few-Shot Dialogue Generation
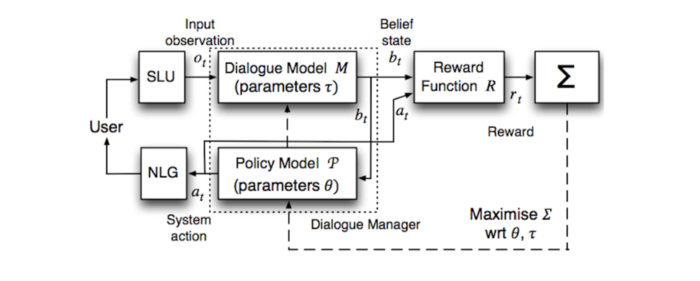
Dialogue generation aims at generating human-like responses given a human-to-human dialogue history. In a conventional task-oriented dialogue system, a response (user’s raw utterance) is taken, via either spoken language understanding (SLU) module or a natural language understanding (NLU) module, and converted to a semantic frame of dialogue acts.
These dialogue acts are sent to a dialogue manager which produces the system’s next action in a semantic frame in accordance with a policy using the dialogue state tracker. Then, through natural language generation (NLG), if chosen by the policy to respond, the semantic frame is transformed into human understandable utterances.
The training of deep learning-based dialogue systems is hugely dependent on large amounts of data, which questions the ability of the system to perform in a real-world environment with limited data.
Hence, ‘few-shot learning’ approaches to data-efficient dialogue system training is introduced for a new domain using a latent dialogue act annotation learned in an unsupervised format from a larger multi-domain data source as proposed by Zhao et al. (2018) (referred to as Latent Action Encoder-Decoder Model).
Latent Action Encoder-Decoder
The development of an unsupervised neural recognition model that can discover interpretable meaning representations of utterances as a set of discrete latent variables can improve the effectiveness of a dialogue system. This is achieved with a better interpretation of the system-intentions and modelization of the high-level decision-making policy that enables useful generalization and data-efficient domain adaptation.
Built upon variational autoencoders (VAEs), DI-VAE and DI-VST discover interpretable semantics via autoencoding and context predicting, respectively. The prime focus lies in learning discrete latent representations instead of dense continuous ones because of their high interpretability.
Discrete Information Variational Autoencoder
Discrete Information Variational Autoencoder (DI-VAE) has been improved upon the traditional Discrete Variational Autoencoder (VAE) through a modification in their learning objective to entertain the anti-information limitation of evidence lower bound objective (ELBO).
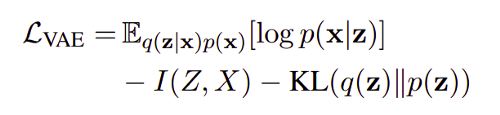
The term KL Divergence in ELBO tries to reduce the mutual information (\(I\)) between latent variables (\(Z\)) and the input data (\(X\)) which explains the anti-information limitation.
The resolution regarding the ignorance of the latent variables during the training phase (anti-information limitation) is to maximize both the data likelihood and mutual information between latent action and input.
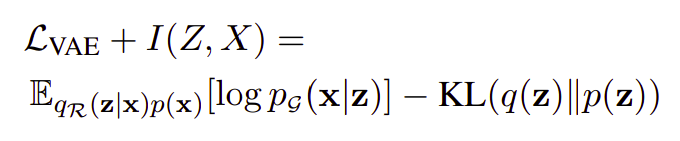
DI-VAE maximizes the ELBO jointly with the mutual information between input data and latent actions. It minimizes the KL Divergence using Batch Prior Regularization which proves to be advantageous over, the usual, Maximum Mean Discrepancy due to its non-linear nature and fundamental difference with annealing.
DI-VAE infers sentence representations by the reconstruction of the input sequence, and hence considered generative.
Discrete Information Variational Skip Thought
The skip thought is a powerful sentence representation that captures contextual information. It uses a Recurrent Neural Network to encode a sentence and then using the resulting representation it predicts the previous and next sentences.
The signals through auto encoding are enriched by extending the concept of skip thought to Discrete Information Variational Skip Thought (DI-VST) that learns sentence level distributional semantics. It uses the same recognition network as DI-VAE to output z’s posterior distribution. The learning objective, as shown, is maximized by the minimization of KL Divergence term.
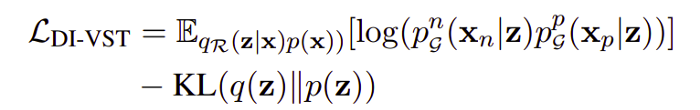
Integration of DI-VAE and DI-VST with Encoder and Decoders
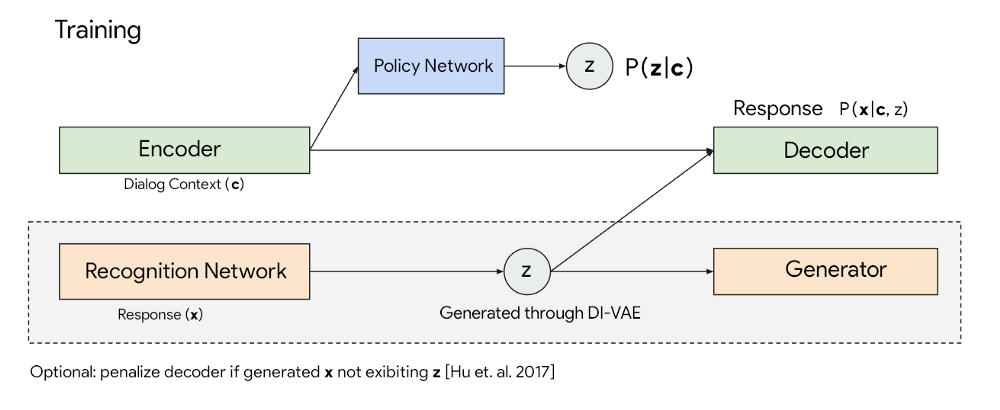
The role of Recognition Network \(R\) is to map a sentence to the latent variable \(z\), and the generator \(G\) defines the learning signals that will be used to train \(z\)’s representation.
Notably, the recognition network \(R\) does not depend on the context \(c\). This design encourages \(z\) to capture context-independent semantics. At test time, given a context \(c\), the policy network \(\pi\) and encoder-decoder network \(F\) will work together to generate the next response. In short, \(R\), \(G\), \(F\) and \(\pi\) are the four components of the framework.
With the discrete latent variable learned by the recognition and generator network, a dialogue context encoder network encodes the context into a distributed representation. The decoder, then, generates the responses using samples from posterior. Meanwhile, policy network \(\pi\) is trained to predict the aggregated posterior from dialogue context \(c\) via maximum likelihood training. This model is referred to as Latent Action Encoder-Decoder (LAED).
Preliminary training trains two LAED models, both DI-VAE and DI-VST. Then, at the main training stage, the hierarchical encoders of both models were trained and incorporated with Few Shot Dialogue Generation Model’s decoder to obtain an extraordinary performance.
Dialogue Knowledge Transfer Network
Goal-oriented multi-domain dialogue systems, after the n-COVID19 outbreak, are widely adopted by industries to cater to the needs of existing as well as prospective customers. The data-driven dialogue systems are in development to reduce the amount of data needed for training. This will prove to save a significant amount of computational costs for enterprises.
Dialogue Knowledge Transfer Network (DiKTNet) is a generative goal-oriented dialogue model designed for few-shot learning, i.e. training only using a few in-domain dialogues. The key underlying concept of this model is transfer learning. DiKTNet makes use of the latent text representation learned from several sources ranging from large-scale general-purpose textual corpora to similar dialogues in domains different to the target one.
A Hierarchical Encoder-Decoder architecture with attention-based copying model is used for few-shot dialogue generation. The main task of this model is, having been trained on all the available source data, to fine-tune on the target data to be further evaluated on the full set of target-domain dialogues. Knowledge Base Information is represented as token sequences and concatenates it to the dialogue context similarly to CopyNet setup. The copy mechanism’s implementation used for such outstanding performance of DiKTNet is the Pointer-Sentinel Mixture Model.
DiKTNet achieves state-of-the-art results with two-stage training:
Pre-training Stage: It involves learning of dialogue action representations to capture the dialogue structure by abstracting away from surface forms. DI-VAE and DI-VST are trained on large sources of dialogue corpora from multiple domains, like, MetaLWOz corpus, in an unsupervised way with the objectives as described above and use their discretized latent codes (for both system and user) respectively in the downstream model at the next stage of training.
Transfer Learning Stage: At this stage, training for the target task begins using the few-shot dialogue generation architecture as described above. Instead of direct domain transfer, domain-general dialogue understanding is incorporated from the LAED representation trained on MetaLWOz at the previous stage. LAED captures the background top-down dialogue structure: sequences of dialogue acts in a cooperative conversation, latent dialog act-induced clustering of utterances, and the overall phrase structure of spoken utterances.
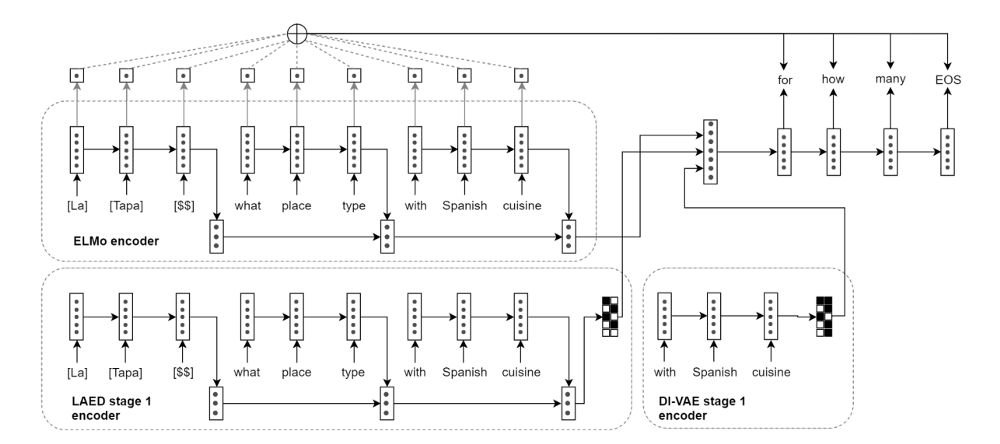
Similar to the Few Shot Dialogue Generation, as described above, the DI-VAE is used for reconstruction of the words, and DI-VST for building the context.
By transferring latent dialogue knowledge from multiple sources of varying generality, a model with superior generalization is obtained for an under-represented domain.
Finally, DiKTNet is HRED augmented with both ELMo encoder and LAED representation and it is the unsupervised discrete sentence representation learning method. It has the flexibility to accommodate itself via any encoder-decoder model and does not require much data to train itself.
Refrences:
- [1910.01302] Data-Efficient Goal-Oriented Conversation with Dialogue Knowledge Transfer Networks
- [1804.08069] Unsupervised Discrete Sentence Representation Learning for Interpretable Neural Dialog Generation
- [1908.05854] Few-Shot Dialogue Generation Without Annotated Data: A Transfer Learning Approach